Meta Circular Evaluators
This page is completely based on the 4th chapter of the famous "Abelsson and
Sussman" course (book: Abelson & Sussman: Structure and Interpretation
of Computer Programs - SICP).
The evaluator, which determines the meaning of expressions in a programming
language, is just another program.
Meta Circularity
A meta circular evaluator for Pico is an interpreter for Pico that is written
in Pico itself. How is this possible? In order to explain this, we just realize
that in fact there are 2 Pico's: the first Pico is the 'real' Pico (whose interpreter
was written in C, but that's not essential at all) and the 'meta circular Pico'
(whose interpreter was written in 'real' Pico). The 'real' Pico is called the
meta level and the 'false' Pico is called the base level Pico. Notice that 'false'
is not really a well chosen word here as that evaluator is a real as the first
one: it runs Pico programs. We will sometimes also talk about the implementing
Pico (i.e. the 'real' Pico) and the implemented Pico (i.e. the 'other' Pico).
According to SICP, an evaluator that is written in the same language that
it evaluates is said to be meta circular.
Studying meta circular evaluators for any language L is a very useful activity
because:
- By studying this volume of L code, you get to know L much better than by
merely studying small code excerpts and standard algorithms.
- By studying the code, we get a a precise definition of the semantics of
L. In fact, the code for the evaluator is the only precise definition of the
semantics. The only drawback of a metacircular definition is that it cannot
be used in practice because the resulting evaluator is too slow.
- Although the evaluator studied is written specifically for L, it contains
the essential structure of an evaluator for any computer language. By studying
and experimenting with one metacircular evaluator, students are acquainted
to the entire discipline of interpreter building is a very accessible way.
- The essence of meta circularity is that one has to understand precisely
one program written in L in order to understand all programs
written in L!
Structure of the Meta Circular Evaluator
The structure of a meta circular evaluator is no different from the structure
of any other evaluator. The only thing special about it is that it is written
in the same language it evaluates. The evaluator consists of a so called 'Read-Eval-Print'-Loop
(or REPL). This is a loop that is started and terminated by the programming environment.
As you might expect, the REPL consists of three parts:
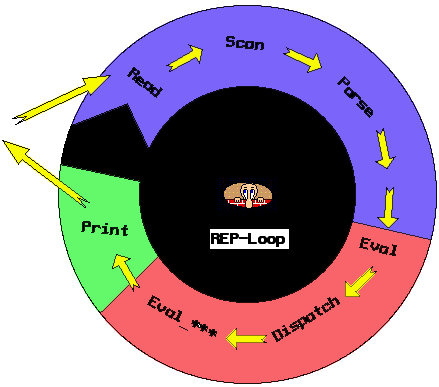
- Read When the user types in a program, this program is just a text,
a meaningless sequence of characters. Before the core of the evaluator can
do something reasonable with it, it has to check whether that sequence of
characters indeed constitutes a valid program. This because many texts can
be rejected as being wrong programs (e.g. because parentheses don't match).
Instead of detecting this during the execution of the wrong program, it is
better to detect it before beginning any execution. This checking phase is
called the reading phase of the REPL. The reader takes a piece of text
that is expected to meet the rules of the syntax of the language. If the text
does not meet the definition of the syntax, an error is generated. Otherwise,
the reader transforms the text meeting the concrete syntax into a tree data
structure, the so-called parse tree. This tree represents the structure of
the program and no longer contains surface syntax like parentheses. The reader
for pico consists of two files representing the scanner (or lexical analyzer)
and the parser (or structural analyzer). The scanner transformes the program
text into a stream of 'tokens' such that all irrelevant information such as
whitespaces and carriage returns have been removed. The parser consumes these
tokens and tries to find the structure linking the tokens in order to build
up the parse tree.
- Eval After reading a string, we obtain a parse tree which is of course
much easier to process than the original string (after all, that's the reason
why we parse in the first place). Therefore, evaluating the program boils
down to performing a tree recursive process on the parse tree. Hence, the
evaluator is a tree recursive process that consumes a parse tree and returns
a Pico value. Each step in this recursive process takes one node in the parse
tree, dispatches over the kind of node (is it a definition, an assignment,...)
and undertakes the appropriate steps to process that particular kind of node.
In many cases, this will require recursive calls to the evaluator. The result
of the recursive evaluation procedure is called a Pico value.
- Print After calling the evaluator, the printer is called. The printer
can be considered the inverse of the reader. It takes a Pico value (a tree)
and prints the value on the screen in a form that makes sense to the Pico
programmer.
Back to the beginning !
This page was made (with lots of hard work!) by Wolfgang De Meuter